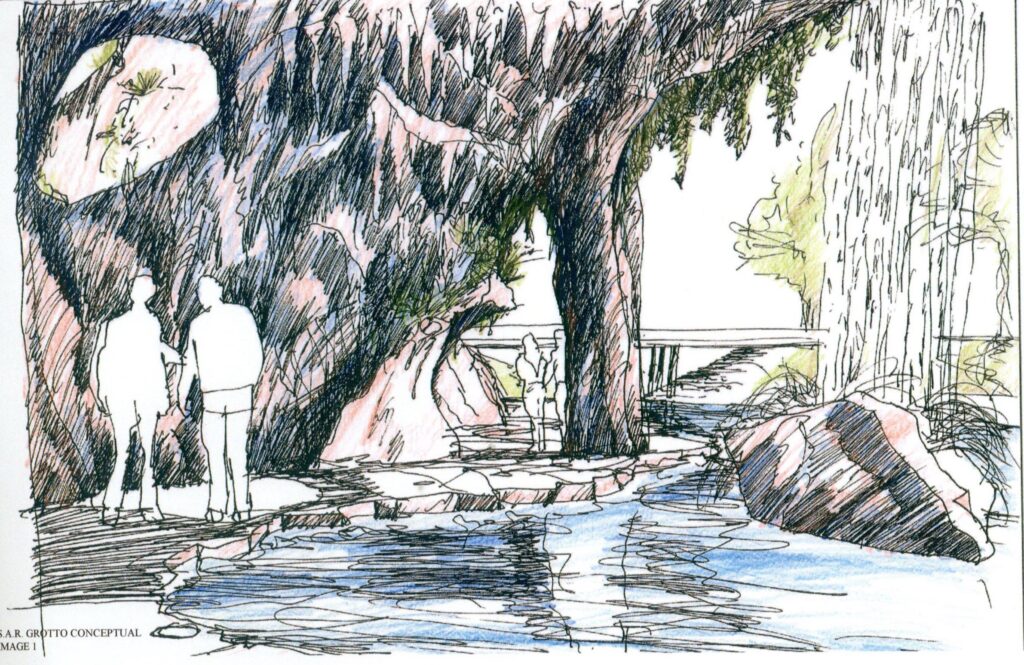
San Antonio River Grotto sketch, Ford, Powell & Carson collection, Alexander Architectural Archives, University of Texas Libraries, The University of Texas at Austin
This past year as the Alexander Architectural Archive’s GRA, I’ve published finding aids for six separate collections to Texas Archival Resources Online (TARO). Those collections are: the Boone Powell collection, the Ford, Powell & Carson collection,the Mardith Schuetz-Miller collection, the Nancy Kwallek collection, the John Covert Watson collection, and the Richard Cleary collection. The first two collections’ finding aids are the culmination of several years’ work by myself, my GRA predecessors, and the entire AAA staff. Boone Powell is a noted architect in San Antonio. His collection includes records documenting his personal and professional life, such as his work on community projects such as Design San Antonio. Ford, Powell & Carson is likewise a noted architectural firm in San Antonio, known for the construction of the Tower of the Americas for the 1968 World’s Fair and its development of the San Antonio Riverwalk. Records in this collection consist primarily of files and drawings related to major projects conducted over the last fifty years. Pictured above is one such example, a photo of a sketch for the San Antonio River Grotto from the Ford, Powell & Carson collection.
The remaining four finding aids are provisional. These collections have not been processed, and their finding aids, while shortened, are intended to boost accessibility to our collections in the backlog. Mardith Schuetz-Miller is an anthropologist and historian who earned her PhD in American Civilization at UT, and her collection contains publication drafts and drawings, specifically concerning the architecture of Spanish Colonial sites in the American Southwest and Guam. Professor Emeritus Nancy Kwallek is a former director of the interior design program at UT, and was a major contributor to the program’s move to the School of Architecture. Her collection documents the history of the interior design program, as well as some of the works of interior designer Everett Brown. John Covert Watson is a noted Austin architect, known for his residences in the Austin area, especially around Lake Travis and West Lake Hills. His collection consists of architectural drawings for a selection of his projects. Finally, Richard Cleary is a Professor Emeritus in the School of Architecture here at UT, and his collection includes records from his own research and publication processes, as well as materials from courses he taught at UT.
Over the past several years, a team at UT Libraries has been developing the UTLARCH GeoData project, a prototype for a new kind of geospatial database that can map and link together data derived from various collections at the Alexander Architectural Archives. In this post, I will summarize our work to date.
The core project team has consisted of myself, Josh Conrad, a graduate research assistant, along with Katie Pierce Meyer, Michael Shensky, and Jessica Trelogan. We have also relied heavily on the amazing data work from UT Libraries staff and students including Grace Hanson, Irene Lule, Alyssa Anderson, Abigail Norris, Katie Jakovich, Stephanie Tiedeken, Beth Dodd and Nancy Sparrow.
Buildings of Texas
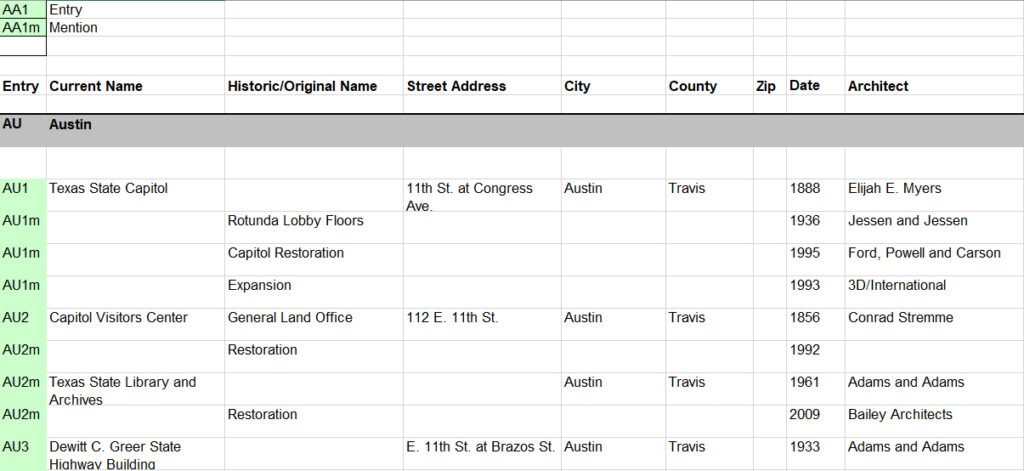
The project began in 2018 after the Alexander Architectural Archives received a new collection donation from architect and historian Gerald Moorhead containing the research and editing material for the two volume book series Buildings of Texas, published in 2013 and 2019. This donation consisted of over 20 boxes of paperwork, 12,000 photographs, and, importantly for our project, a series of eight Excel spreadsheets cataloging over 5,000 places represented in the book series. These spreadsheets included addresses, place names, dates of construction and renovation events, as well as architects and other contributors to these building events.
The Buildings of Texas spreadsheets provide a wealth of data about a wide range of architectural projects throughout the state, including many projects represented in other AAA collections. The AAA projects database and finding aids also store a lot of information about the various architectural projects represented in the collections, but many gaps exist in AAA data, especially geographic information such as addresses and coordinates which were not included on donated items such as drawing sets. With the acquisition of the Buildings of Texas datasets, the intriguing possibility arose of filling in these gaps by linking Buildings of Texas data to existing AAA projects data.
From this seed of an idea, the project concept expanded: why not connect geodata from other AAA collections as well, such as the recently digitized David Williams photography collection and Atlantic Terra Cotta Company photography collection, both now hosted on the UT Libraries Collections portal. Numerous other un-digitized architectural datasets also exist in AAA collections which in the future may be able to be included in this growing linked database, such as the Texas Architectural Survey collection and the historical surveys conducted by architects and historians such as Eugene George and Wayne Bell. Could we include data from outside of the AAA as well?
Linked data model
These early brainstorms coalesced around a plan for new kind of geospatial database that could store and display place data from various linked datasets together on a map. We saw this concept as akin to pre-digital geographic indices such as atlases and gazetteers. We also envisioned this database as a kind of spatial finding aid that researchers could use to find all the items about a place such as photographs and drawings that may be held in multiple collections. Further, if this potential geodatabase will be digital, we could use it to develop map-based digital exhibitions and other kinds of library discovery tools.
We explored a variety of database models for representing this diversity of data. A single data table would not be sufficient. Places represented in AAA collections are complex and involve multitudes of contributing individuals. Our data model would need to be flexible and allow one-to-many relationships throughout. In architectural data, places are often associated with a number of specific events in time such as dates of construction and renovation. Further, each event is often associated with multiple different people and companies such as clients, architects, builders, and other contributors. And, to add further complexity, events are documented by multiple different artifacts, such as photographs and drawings. We wanted to develop a spatial database that could link people and artifacts to places while also being able to store temporal data that could contextualize them within the history of that place.
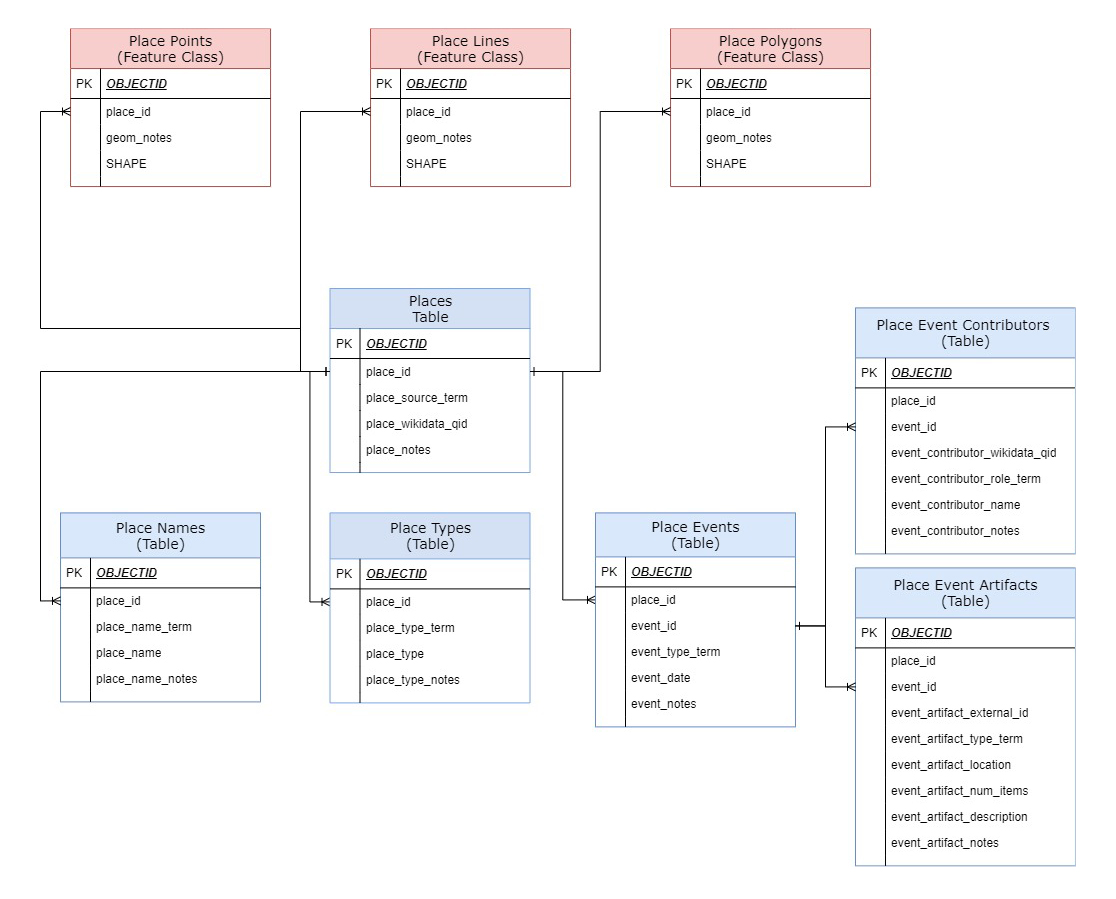
Below is the Entity Relationship Diagram (ERD) of our prototype data model. Centrally, the core table is the Places table. Places represented in this table are labeled with the name of the collection from which the data originates (place_source_term). In order to map the data with a geographic information system (GIS), we connect each place to its geographic representation, a point, line or polygon located somewhere on earth. The three tables at the top (in red) are the spatial tables, or “feature classes” in GIS lingo, that are required by the GIS. One feature class represents points, one represents lines and one can represent polygons. Place data is often represented with a point, essentially a map pin located on or near the place’s location on earth, but places can also be represented with lines, in the case of roads or trails, or polygons in the case of building outlines, land parcel boundaries, and neighborhood boundaries.
The core places table is then connected in a one-to-many relationship to various attribute tables (in blue) that can store multiple values per place. In the Place Names table, places can have many names, such as current and historic names as well as addresses. In the Place Type table, places can have many different types or uses, such as residences, commercial buildings, public buildings, and landscapes such as parks and neighborhoods. Further, places can be sites of multiple events over time, including but not limited to construction and renovation events, documentation events such as the photographing and drawing of that place, and cultural events such as celebrations and commemorations. Thus, the Events table, as our model’s temporal table, stores the dates and event data associated with each place. From the Events table are connected two more attribute tables: the Contributors table, which stores names of people and companies associated with each event; and the Artifacts table, which stores the data about collection items associated with each event.
Within this spatial and temporal data model, multiple data sources can be combined. However, if two or more sources represent the same place, that place will be represented by multiple unconnected records in the places table, one record for each source. Ultimately we want to be able to match these records so that researchers can view all the data available about each place. Preliminary ideas from our team included the idea of creating a “Unique Places” table where matching places could link to a single shared place record, essentially an authority record that could store a standardized geographic representation for that place. We would also want to create an authoritative “Unique Contributors” table.
The prospect of creating our own authority files brought up the question of how we might work with, or contribute to, existing authority file databases such as Getty Vocabularies, who manages two authority ontologies relevant to us, the Art and Architecture Thesaurus (AAT) and the Union List of Artist Names (ULAN). Further, as a means to broaden representation and allow for multivocality and multiplicity, we felt that we should also contribute our authority records to the linked open data community via Wikidata.
Wikidata
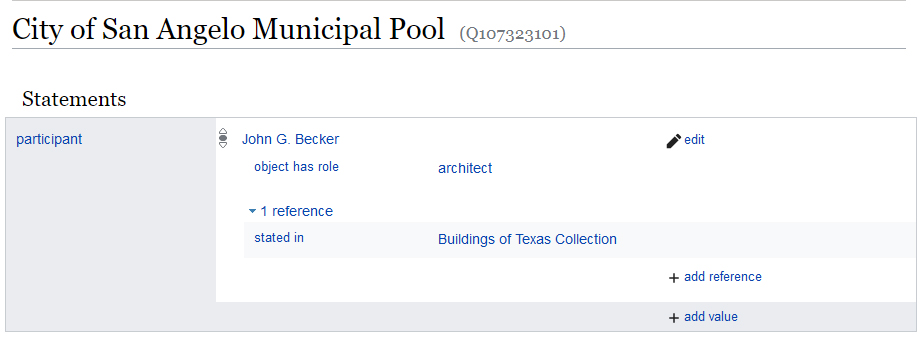
I usually think of Wikidata as the database version of Wikipedia. Similarly to Wikipedia, Wikidata is an open collaboratively-edited platform developed by the Wikimedia Foundation using the CC0 public domain license. But whereas Wikipedia is composed of records of various entities and concepts written in an encyclopediatic narrative prose, Wikidata represents unique entities as structured database records with a data model that they call a “knowledge graph”. A graph data model, which I have also heard called a linked data model, a network model, an ontology model, or an object-oriented model, is an alternative data model used by encyclopediatic knowledge databases and newer authority file systems such as Getty Vocabularies, the Library of Congress Linked Data Service, the Virtual International Authority File, the CIDOC Conceptual Reference Model, and Wikidata. In a graph model, data is stored, not in fixed table rows like in traditional relational databases, but rather as a series of “triples” composed of two objects (or “nodes”) and their relationship (or “edge”), and stored in a specialized databases called triplestores. In this more-flexible structure, each unique object can have many different relationships with many other objects. In Wikidata, item records are able to have many different attributes which are each linked to other unique items. The result is a flexible hyperlinked database. The image below shows an example of a Wikidata record containing an attribute that is in turn linked to another Wikidata record, forming a network.
Because Getty Vocabularies and Wikidata both use a linked data model, we are able to match and link records from our different data sources by connecting, or “reconciling”, each record to its authoritative Getty or Wikidata record. However, because Wikidata offers an open-source collaboratively-edited platform, if a Wikidata record for a place or contributor does not exist, we can simply create it on the fly using the Wikidata reconciliation API and Open Refine. This important feature distinguishes it from Getty Vocabularies which is not a publicly editable database (though they do accept new data through partnerships with libraries). Because it allows us to directly manage records, Wikidata can essentially become integrated into our data infrastructure and workflow. In other words, Wikidata can simply become our authority file. In this configuration, our data model is greatly simplified. As shown the ERD above, instead of creating new “unique” tables, the Places and Contributors tables both contain attributes labelled wikidata_qid in which we simply store the Wikidata identifiers (QIDs) that represent each authority record.
Database infrastructure
Because our ultimate goal is to create a geospatial database, we required a GIS database infrastructure. A critical component of this project, one which really made everything possible, was our ability to use the ArcGIS geodatabase and server that UT Libraries ITS has recently installed to support the creation of the Texas GeoData Portal. UTL ITS has been providing the libraries with an incredible data infrastructure from which to build new innovative kinds of discovery, access and digital preservation tools. We are also forever grateful to UT Libraries GIS experts Michael Shensky and Jessica Trelogan for being a part of our core team and teaching us how to navigate the complex matrix of settings and workflows required to host data within this infrastructure.
The GIS infrastructure is essentially composed of three components: a ArcGIS enterprise geodatabase built with Microsoft SQL Server, the ArcGIS Server, and ArcGIS Online. Data tables created on the SQL server are linked to a GIS feature service which can be then added to an ArcGIS Online web map as a set of GIS feature class and tables. Any updates made over time to the core data tables are then automatically updated in the web map.
In order to populate and update the geodatabase over time, our team established a documented data processing workflow that extracts the original data source, transforms it into our linked data model (including reconciling with Wikidata), and loads it into our database infrastructure. This Extract-Transform-Load workflow involves the combined use of the data processing tool Open Refine as well as ArcGIS Pro and can be applied to new datasets in the future.
Results
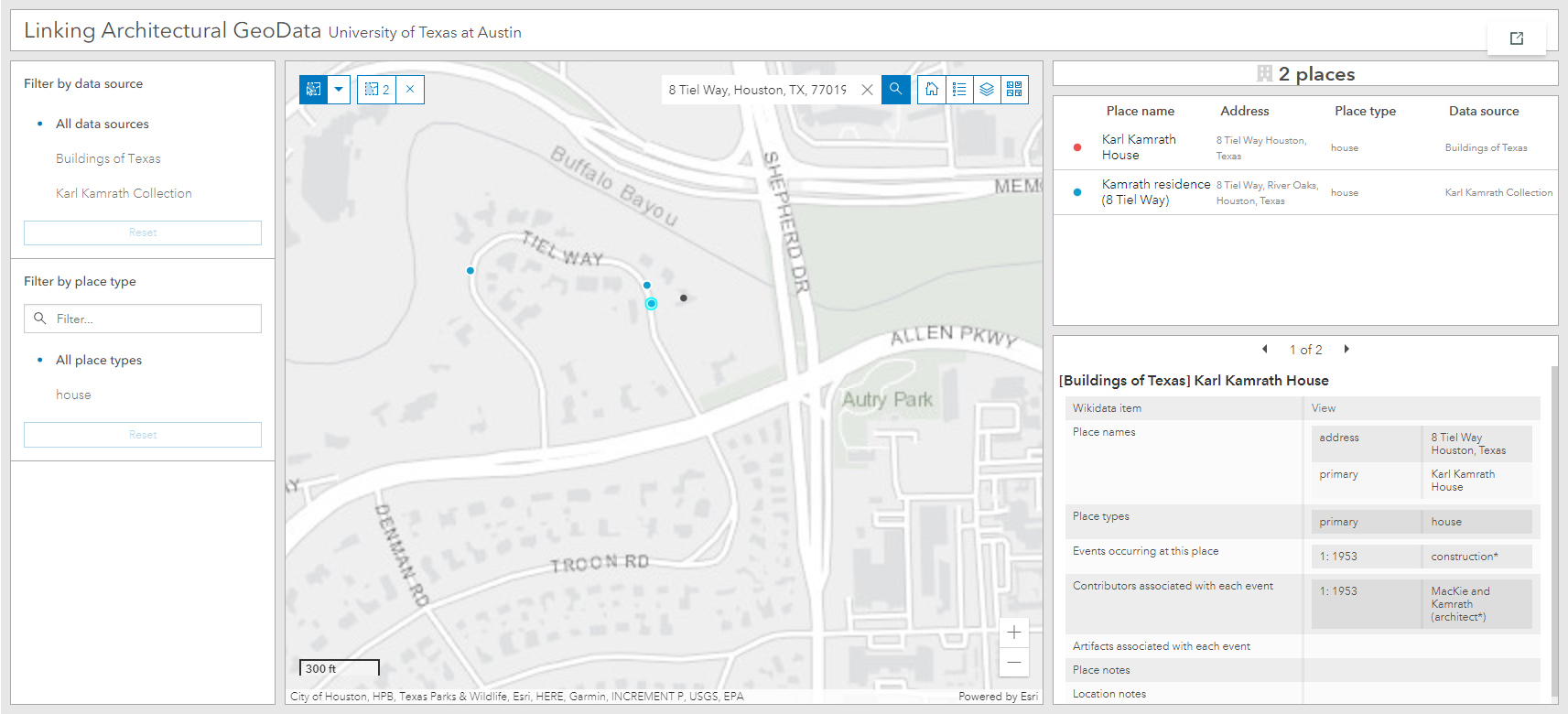
To date, we have uploaded three datasets into the new geodatabase: the Buildings of Texas Collection, as well as two datasets exported from the AAA projects database representing the Karl Kamrath Collection and the Volz & Associates, Inc. Collection. As part of this process, we have created nearly 7,000 new Wikidata records representing both people and places.
Below is a screenshot of our ArcGIS Online web map and interactive data dashboard. The image shows an example of a house represented in two separate datasets, linked spatially by having the same point coordinates as stored in Wikidata. This house, located at 8 Tiel Way in Houston, was designed by Karl Kamrath. The Kamrath dataset provides data about the drawings he produced for the project which we represent in the geodatabase as “drawing” events using the date at which the house was drawn (as recorded on the drawings). The Buildings of Texas dataset includes data about the home’s construction, which we represent as a separate “construction” event. Together the two events begin to provide a more temporal depiction of this place than each dataset does alone.
The two datasets from the AAA projects database provided us with a workflow template for adding other AAA projects datasets in the future. Digitized datasets extracted from UT Libraries Collections portal metadata are next. Over time we hope to continue refining and filling in the gaps in each of these data sources by developing new editing workflows using the interactive tools in ArcGIS Online. As both the Wikidata and ArcGIS platforms improve over time, we hope to find new ways to link the two more intimately. Currently, for example, ArcGIS Online is not able to asynchronously query external APIs such as Wikidata, so we must continue to store authority data locally. ArcGIS developers has also started integrating graph data models into their products which may allow us to migrate from our relational data model and more-fully embrace linked data practices.
We are excited to be a part of these developing technologies and hope to continue experimenting with new ways of sharing and linking architectural data. Be sure to visit our project dashboard as well as our project StoryMap which explores how linked architectural data can be useful for new research.
What does an archivist do when the archives are closed?
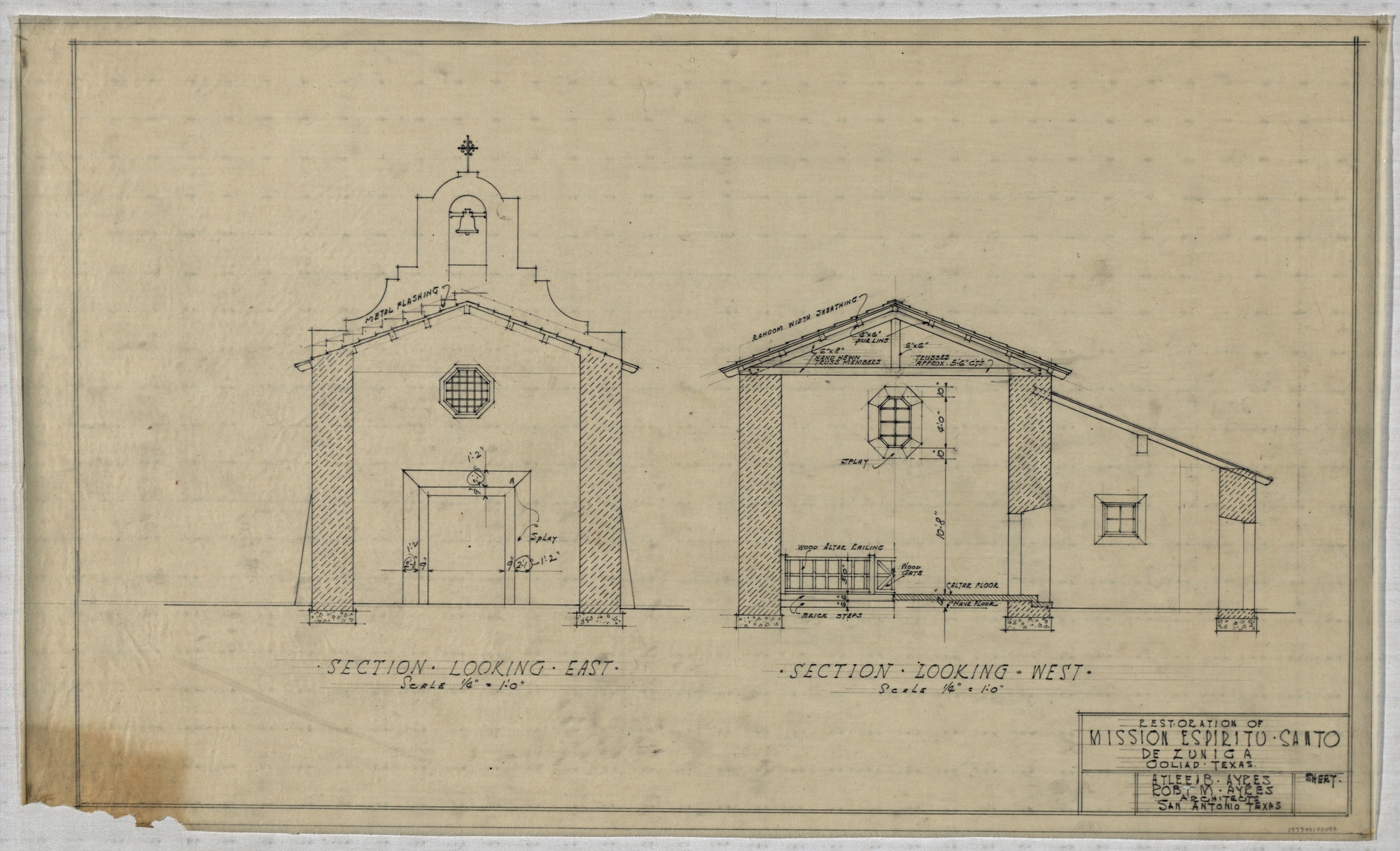
Mission Espíritu Santo de Zuniga restoration drawing, 1933
Along with institutions across the globe, the Alexander Architectural Archives and Architecture and Planning Library closed our doors in March for the safety of students, staff, and visitors. Usually we spend our days surrounded by the Alexander’s collection of papers and books at Battle Hall, physically tied to the materials we work with. While we miss the stacks (and each other!), the transition to remote-work presented the perfect opportunity to focus our attention on digital projects at the archives.
Digital work gave us something to keep our hands full, but, more importantly, it gave us a way to continue to make archival resources available to researchers, also facing the challenges of remote work. Contributing to the University of Texas Libraries’ Collections Portal offered the best of both worlds. This recently launched Digital Asset Management System (DAMS) provides a platform for UT repositories to store and describe their digital materials, and share them with the public.
Screenshot of the collections portal
Luckily, this isn’t our first rodeo when it comes to digital projects at the Alexander. For as long as digital technologies have existed, the archival profession has been brainstorming ways to both preserve these technologies and take advantage of them to make archival materials more accessible. In 1999, the Alexander launched an online digital exhibit titled, Spanish Colonial Architecture as Represented in the Alexander Architectural Archive, described as “a collection of digitized drawings and photographs of eighteenth-century Spanish missions and [the] San Antonio’s Governor’s Palace. These records, dating mainly from the 1920s through the 1950s, reflect how the structures looked before various efforts of restoration and reconstruction. Selected from collections within the Alexander Architectural Archive, they include works by Harvey P. Smith, Stewart King, Ayres and Ayres, Robert Leon White, and measured drawings by UT Austin School of Architecture students in the Texas Architecture Archive”.
Twenty years later, this collection of digital scans is gaining new life on the Collections Portal. In my role as a Graduate Research Assistant at the Alexander, I’ve been immersed in a world of arches and colonnades, uploading assets from the Missions exhibit into the DAMS and adding descriptive metadata.
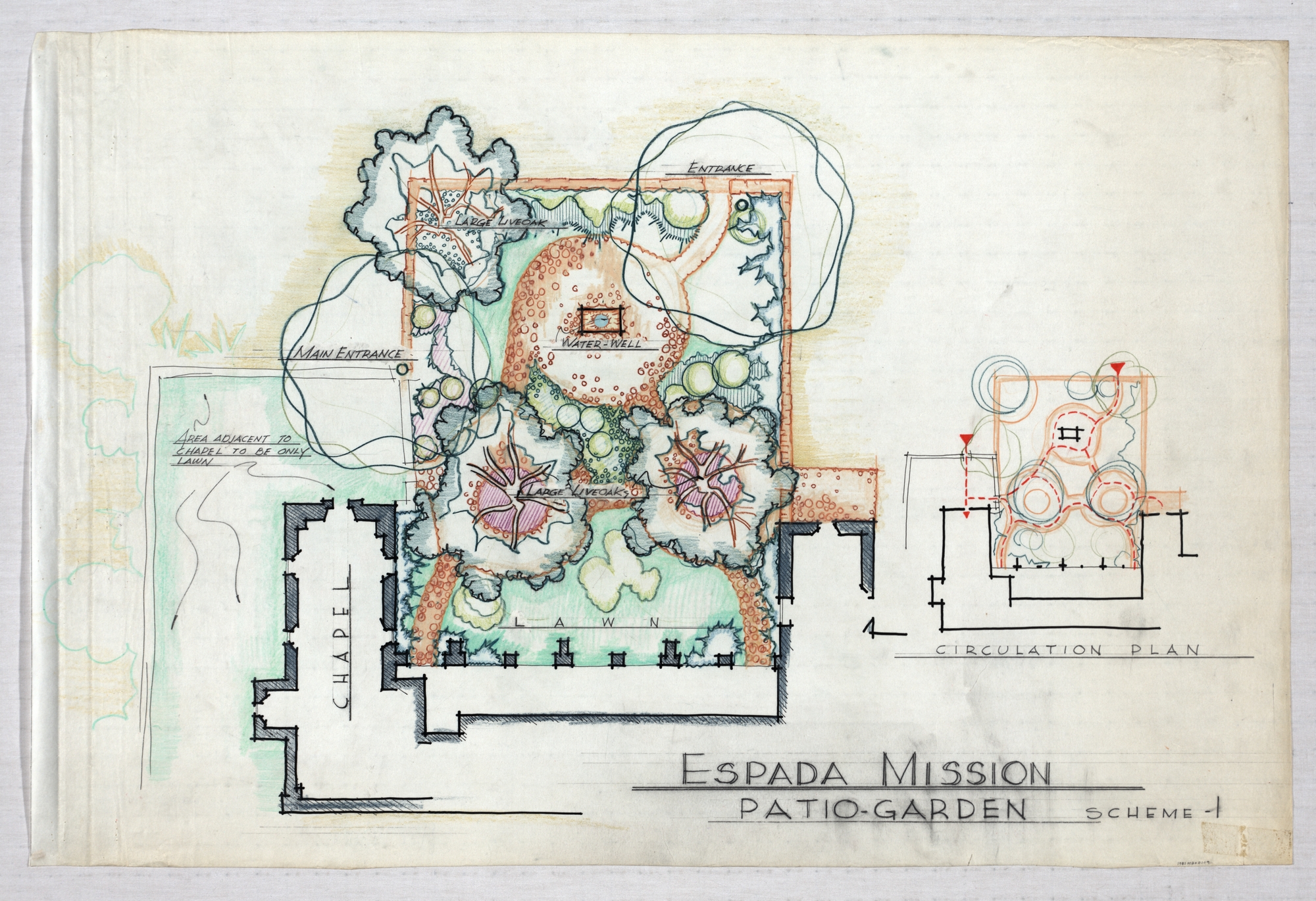
Mission San Francisco de la Espada, drawing of patio
Following UT’s shutdown, the staff at the Alexander shifted our focus to remote projects, including working in the DAMS to ingest an array of items, from floorplans to historic photographs. With over 2,000 combined items from the Alexander Archives and Library, our collection is only growing. As researchers continue to limit travel and conduct their work remotely, access to online resources has become more important than ever. Even as UT begins to implement new safety strategies on campus and we consider plans for reopening the archive, digital portals will remain a vital access point and a way for both institutions and researchers to see archival materials in a new light. When it comes to the digital, we as archivists are in it for the long haul, rain or shine, just like our commitment to preserving traditional paper artifacts.
We look forward to welcoming you back to Battle Hall in the future, and in the meantime, we hope you’ll enjoy browsing our materials virtually via the Collections Portal.
Sources:
Ayres and Ayres, architects (architectural firm), Mission Espíritu Santo (Goliad County, Tex.) (client). Mission Espíritu Santo de Zuniga: restoration, section. 1933. “Mission Espíritu Santo de Zuniga: restoration, section – Collections”. University of Texas Libraries Collections. <https://collections.lib.utexas.edu/catalog/utlarch:482b5b97-8213-487d-90b4-36908283d82f> (25-August-2020).
Stewart King (architect), Mission San Francisco de la Espada (San Antonio, Tex.) (client). Mission San Francisco de la Espada: patio, circulation plan, scheme 1. undated. “Mission San Francisco de la Espada: patio, circulation plan, scheme 1 – Collections”. University of Texas Libraries Collections. <https://collections.lib.utexas.edu/catalog/utlarch:894ff646-076b-46a4-b3a5-d04d322768d1> (26-August-2020).
Hello, People of the Blogosphere! We figured it was time to provide an update on the efforts to digitize our copies of the journal Southern Architect and Building News. The bottom line: all our issues of Southern Architect are now available on the new University of Texas at Austin Collections website! There are still some kinks being worked out and changes being made to the site, but there are now hundreds of items available from institutions across campus for you to peruse.
One thing worth highlighting about the site is the sheer quality of the images. Particularly noteworthy is that the images lose none of their quality when users zoom in. Not only that, but now you can invert images to be negative, adjust saturation and brightness, rotate the image, and more.
Screenshot of the University of Texas at Austin Collections website, showing an unedited image This is the same page in the journal as pictured above, only zoomed in on the images and with the colors inverted so that the images of the plans are clearer.
Additionally, you can overlay the metadata for the issue over the image itself, which is a very useful feature when you are in the midst of reading the journal or looking at the images. This means you can see all the information you might need without having to abandon the image you are on or losing any edits you might have made to the image.
Here you can see the overlay of metadata over the image.
There are also several different ways of viewing the images, including scroll view and book view. This allows you to choose the format that best fits your needs, whether you want to read the article as if the journal was in your hands (book view), or see numerous images at a time and essentially flip through the whole journal several pages at a time (scroll view).
Book viewScroll view
There’s tons to explore on this website. There’s also still kinks to be worked out. But please go and look at these amazing online collections from us, the Alexander Architectural Archives, and our friends around UT Austin!
Source: Society for Commercial Archeology records, Alexander Architectural Archives, University of Texas Libraries, The University of Texas at Austin
Introduction
This post is part of a series on personal collection management. The series provides tips and tricks to Society for Commercial Archeology (SCA) members for preserving and organizing their personal collections of photographs and print materials, and digitizing these items.
Personal collections management borrows best practices from collecting institutions like archives, libraries, and museums, scaled down for an individual’s needs. Following a few simple personal archiving guidelines can help preserve your memories into the future, keeping them accessible to the next generation.
In the Spring of 2019, I produced a Records Management plan for the SCA’s administrative records, which are housed at the Alexander Architectural Archives, University of Texas Libraries. These articles on personal collection management supplement the institutional Records Management tool, so that the personal materials of SCA members can be cared for at home, even outside of a formal archive.
Source: Society for Commercial Archeology records, Alexander Architectural Archives, University of Texas Libraries, The University of Texas at Austin
Let’s Get Started!
A picture may be worth a thousand words, but only if it’s preserved. For many of us, our photographs, film, and slides contain our most cherished memories and familial ties. But, all too often these photographs sit neglected in damp basements, stuffy attics, and crumbling shoeboxes. The tips below will help your photos live their best life.
Handling
Do not touch the image side of the print directly, to avoid leaving fingerprints and oils from the skin
For best practice, wear thin cotton or nitrile gloves
Storing
Storage is the foundation of photo preservation. The right storage can be the difference between a photo that lasts a lifetime, and one damaged beyond repair.
Store your photos in acid free boxes or envelopes
For extra protection, photos can be layered between sheets of acid free paper, or slipped into clear archival envelopes
Store negatives in acid free envelopes
Avoid storing photos in spaces with wide fluctuations in temperature or humidity, such as attics, basements, or garages. As one blogger puts it: “A good rule of thumb is storing photos where you are also comfortable: not too hot, cold, wet or dry.”
Store photos in a well-ventilated area
Avoid storing photos or photo boxes in direct sunlight
Avoid using paper clips or rubber bands to bundle photographs
When storing photos in boxes, avoid “dead space” which will cause your photos to tip and lean. This can bend your prints, and mix them up out of order. Fill the dead space with folded pieces of stiff acid-free paper.
Similarly, avoid packing prints or slides too tightly into a box. Give them a little breathing room so that the materials are not stressed or damaged by constantly pushing against one another.
Labeling and Organizing
Labeling your photos may feel tedious in the moment, but it can save you from pain and confusion down the line. Have you ever looked back on an old photograph that you took or one taken of you, and had no recollection of the moment? Or what about inheriting a box of old family photographs, without any idea of who the photos depict or when they were taken? Our memories aren’t perfect, but thankfully, labeling can step in for us.
Types of information you may wish to include in the label:
Full names of people in the photo
Date
Location
Occasion
Photographer
Use gentle pressure to label the backs of photographs at the lower border. Avoid pens which require a forceful hand, as the pressure can damage your photo.
If labeling each individual photo is too time-consuming, label boxes or envelopes which contain photos that are part of a set. (Best practice is to label the envelopes before placing the material in them).
There is no single “correct” way to organize your photos. Chronologically, by person, by occasion? Choose a method that makes sense to you, and will make it easy to find the photo you’re looking for in the future.
Displaying and Sharing Photos
Storing photos for the future is great, but what if you want to enjoy your photos in the moment?
If you want to frame a photo for display, consider making a copy, rather than displaying the original. This way you can enjoy your photo everyday, while the original is protected from light damage.
Storing photos in an album is generally not recommended. Album materials like glue, cardboard, and plastic, can damage your photos. Instead, scan the photos and produce an album with the digital scans (through services like Shutterfly, Mixbook, or Amazon photos), or make photocopies for an album. The originals can then be left in protected storage.
Look for acid-free frames, mats, and albums.
Source: Society for Commercial Archeology records, Alexander Architectural Archives, University of Texas Libraries, The University of Texas at Austin
Further Resources
Looking for more? This section links to lots of helpful outside resources.
Wondering how to take care of a collection of photos that’s already experienced damage? Below are resources for addressing common types of damage or degradation.
As an alumni of the College of William & Mary, I was happy to find not one, but two biographies on Sir Christopher Wren in the Architecture & Planning Library Special Collections. For those who don’t know, the (current) Religious Studies building at William & Mary, and the oldest academic building in America, was named after and designed by Sir Christopher Wren. The Wren Building adorns much of the College’s iconography and is the section of the campus most closely connected to Colonial Williamsburg, thus being the first thing most tourists see when they encounter campus. Having spent more of my life associating the name Christopher Wren with a building and not a person, I was excited to learn more about the man.
Published in 1923 to coincide with the 200th anniversary of his death, Lawrence Weaver’s Sir Christopher Wren: Scientist, Scholar & Architect opens with “on the 20th October, 1632, Christopher Wren was born in the…”, confirming it’s the standard, by-the-numbers biography that the title promises you. (1) Each chapter heading cleanly points you to the section’s subject matter, whether it’s “family life,” “St. Paul’s Cathedral” or “Oxford career and early inventions.” It’s a solid example of the type of biography/non-fiction that no longer exists, the one where the author will put the greatest possible effort into making it seem like they have no opinion whatsoever on the subject. In Scientist, Scholar & Architect Weaver assumes you, the reader, know that Wren is a Great Man, so that’s not what he’s going to argue. Instead, he crafts a narrative around how a Great Man expressed his innate Greatness.
Lena Milman’s Sir Christopher Wren is on the same laudatory bent as Weaver’s book. Like Weaver, she structures each section around an individual project or a distinct phase (college, final years, etc.). She does call to consider how “strange” it is that Wren “had no architectural practice in his early life” despite his immediate success when he adopted architecture as a career. (55) Yet she does not really interrogate that emotion further, keeping the biography on the rails of telling Wren’s life story. Published 15 years apart, Milman and Weaver’s biographies work as good examples of a pre-modernist form of biographical writing.
Funnily enough, I could not find a single mention of William & Mary’s Wren Building within the pages of either Sir Christopher Wren biography. The British origins of both texts likely account for that, considering that both writers would probably want to highlight works on the home turf as opposed to the one in the former colony. Despite the dated content of the writing, both texts also have very well-done illustrations. In the Milman text, it’s some lovely black-and-white photographs; in Weaver, it’s some beautiful ink drawings, which I’m unsure if they were crafted by Weaver or an uncredited artist.
Happy Wednesday everybody! New Graduate Research Assistant Colin Morgan here, bringing back the New Books segment of Battle Hall Highlights! Today, I want to highlight one of my favorite books to arrive at the Architecture Library since I started working. Dutch photographer Nico Bick‘s Parliaments of the European Union comprises of thirty photographs of European parliamentary houses, twenty-eight for each of the member states, two for the European Union’s parliament. Outside of two brief introductions, there’s no text in the book aside from captions noting the name of the country and the name of the building. The interiors Bick captures have to speak for themselves.
And united in one bound volume, they do speak. Countries whose histories have featured the accumulation of wealth and notable royal bloodlines, like Spain’s Congreso de los Diputados, hold massive portraits, statues, the country’s crest. The book’s size (it’s a folio) and fold-out style (each photograph folds out onto three or four page, with clear demarcations paneling that section of the photo within the page) fit well with Bick’s human’s-eye-view style of photography. In looking at the photograph, your eye has to crane up the way your head would have to if you were in the actual room, allowing a stimulation of experiencing the overwhelming decor in person. Without a single human face in any of the photographs, the power of these states are shown, not told.
States without that extensive history of wealth have more office-like, anonymous parliaments. The state exists as a functionary device, not as something integral to the identity or culture of the nation. Lithuania’s Seimas, for instance, contains no mark of the nation’s history beyond a crest and the flag. The photograph’s size provides plenty of negative space for the upper two-thirds, as the parliament’s white wall dominates the upper levels of the photograph. Your eye is kept to the bottom, gliding along the chairs and desk on the ground. For parliaments where your eye is mainly focused at one level, you would notice that the most common motif in the book is the presence of computer screens.
Without a human presence, the high number of screens, for the majority of parliaments in the text one per chair, become the photograph’s subjects. Even more so than international histories, computers are the “main character” of Parliaments. The screens, just as much as the European Union’s parliamentary building, are what allow these states to connect with one another. Without explicitly dating the parliaments’ construction in the captions, Bick’s book presents them all as modern structures, with the reader contextualizing the spaces. The modern structure, just like the modern state or the modern economy, can no longer exist in isolation. The interior photographs of buildings dozens or hundreds of miles away from each other highlight how connected they all are.
You can put Nico Bick’s Parliaments of the European Union on hold at the Architecture & Planning Library here.
Cover of Built in U.S.A. (Source: Museum of Modern Art)
Written to accompany Art in Progress, the Museum of Modern Art’s fifteenth anniversary celebration exhibit, Elizabeth Mock’s 1944 book Built in U.S.A. is a portrait of an institution granting itself a victory lap for it’s role in establishing then-modern tastes. Taking their taste-maker status for granted, Built is the Museum’s attempt to assert itself as a great enough authority to not only say what is worth the audience’s time, but to lay out the foundations of the modern architecture canon. Mock, curator of Art in Progress‘ architecture section, uses her introduction to set-up a vision of the “modernist architect” as an individual whose work can walk in perfect balance between “present conditions and future needs.” (9) The utopian-minded ‘modernist architect’ works at odds with the skeptical public, who can only think of the “heat bills” and “glare” that result from the glass-heavy modernist home design. To Mock, these shallow critiques of modern architecture are born out of ignorance, critics who think all of modern architecture can be reduced to “large areas of glass.” (21) Her introduction posits a conflict between the modern style and the cult of practicality. Written in wartime, Mock condemns the point-of-view that states that architects are only there to provide “trimmings,” using the fifty examples in the text to show how architects straddle the line between the practical and the aesthetic. (9)
The Museum of Modern Art, as celebrated on pg. 88 of Built in U.S.A. (Source: Museum of Modern Art)
The subsequent two-thirds of the text showcase the fifty American buildings highlighted in the exhibit. Including several photographs of each structures’ interiors and exteriors, Mock also includes a basic floor-plan. Alongside the visual aspects, Mock features critical notes for each work highlighted. The book functions as a useful source if you are looking for contemporaneous reactions to buildings like “Falling Water” or “The Red Rock Amphitheater.” Perhaps the most striking choice in the text, considering the publisher, is Philip L. Goodwin and Edward D. Stone’s design for the Museum of Modern Art. Praising the architects, the notes also make a point to distinguish the museum as a “flexible” museum, distinguishable and new from the “static collections” that defined art museums in the past. (88) Built writes of the Museum’s architecture as essential to its functionality as a new type of museum.
For additional context around Art in Progress and Built in U.S.A., the Museum of Modern Art has recently provided scans of the three 1944 press releases promoting both to the general public. The best of the three articulates the goals of Built so well it is just as good of an introduction as anything within the text itself. Starting off with a quote from Park Commissioner Robert Moses debasing the Municipal Asphalt Plant (highlighted in Art in Progress and Built) as “horrible modernistic stuff,” the Museum holds it in regard as “one of the buildings… which best represent progress in design and construction during the past twelve years.” In the press release, Moses functions as a real-world version of the abstract ‘public’ Elizabeth Mocks talks about in her introduction. In openly clowning this establishment figure, the Museum not only heaps praise upon the artist, but on itself as a taste-maker. Built in U.S.A., and the marketing surrounding the exhibit and text, establishes an ‘us vs. them’ narrative with the stakes being the aesthetic, and the soul, of a nation. All of the materials the Museum of Modern Art has shared related to the Built in U.S.A. section of Art in Progress are essential to understanding what the discourse surrounding architecture was like in the mid-20th century.
You can read Built in U.S.A. in our Special Collections (or even in the PCL stacks!). Or you can read a PDF (as provided by the Museum of Modern Art) here, further exploration of the Built in U.S.A. section of the Art in Progress exhibit can be found here.
Hello. It’s Abbie again, back with another installment on processing and publishing the Volz & Associates, Inc. collection. I recently had the opportunity to present on this collection at The University of Texas’ 2019 Digital Preservation Symposium, where I discussed some of my solutions to born-digital access and preservation issues.
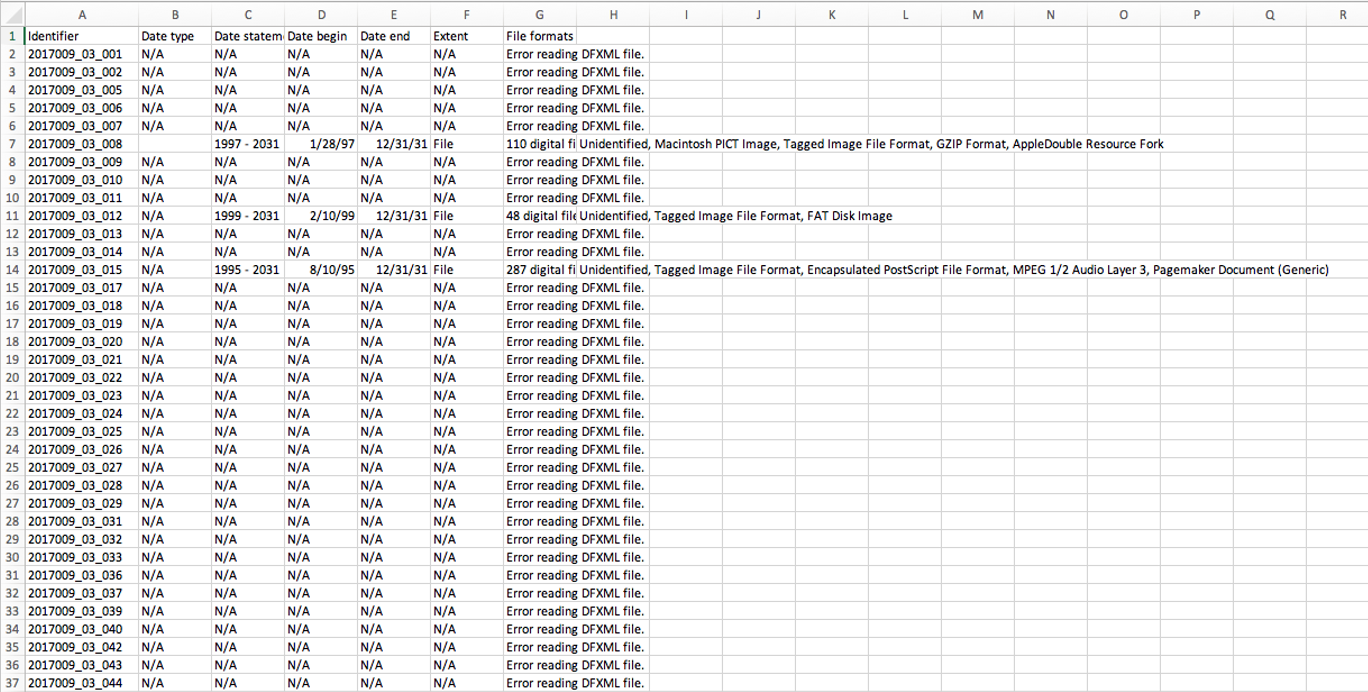
In the course of processing this collection, some of the most significant roadblocks were related to problematic disk images and metadata generation. These revolved around two distinct media types: zip disks and CDs. The collection contains 85 inventoried zip disks. When these were imaged and analyzed in BitCurator, the report came back riddled with error messages. Even though the disk images had been generated successfully, something was keeping fiwalk from generating the correct metadata. This made it impossible to determine necessary information like disk extent, content, and the presence of possible PII or malware.
Results for the zip disk analysis. Not what you want to see!
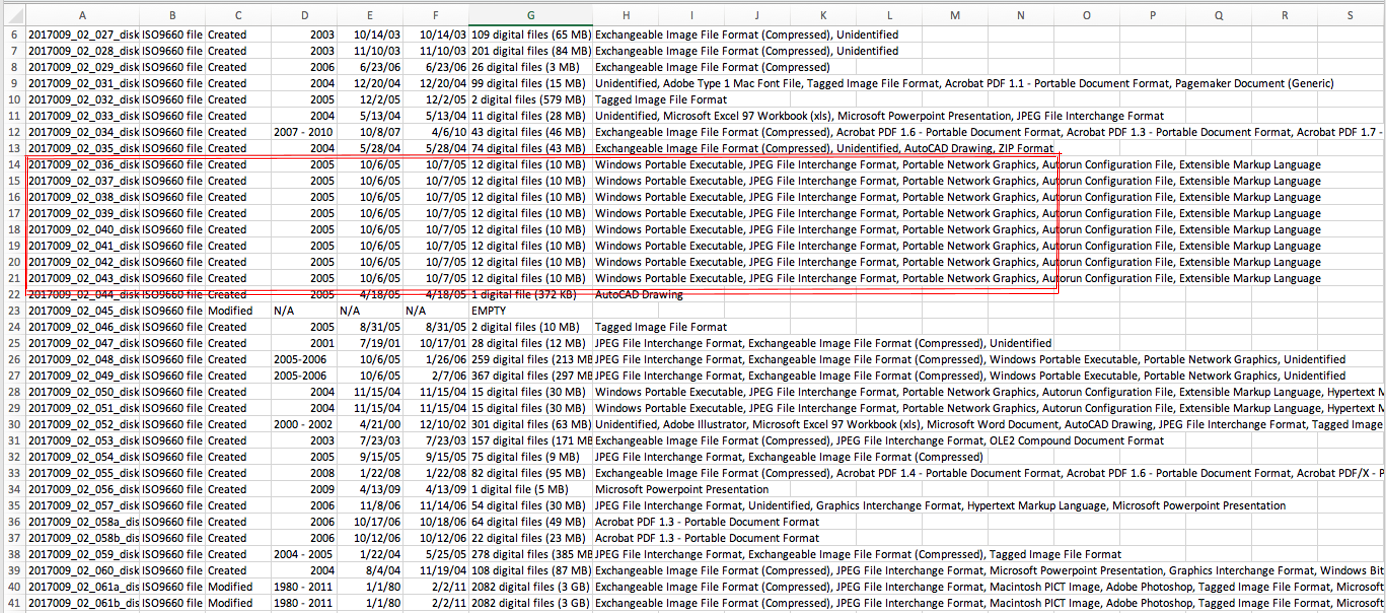
When processing CDs, I noticed a group of about a dozen disks each had the exact same metadata. While some similarities are expected, I thought it was strange that that many disks from different projects could each have identical specs. I analyzed the disk images and physical disks and found that they were all CDs of photos processed by the same company. The original content of the disks had been overwritten by the company’s built-in structural and technical metadata, making the disk images virtually useless for research purposes. However, when these disks were mounted in FTK Imager, a write-blocked environment, it became clear that the original images were still extant – they just weren’t being picked up in the disk images.
Optical disks with identical metadata.
In both of these cases, I knew that the original content could be reached but didn’t know how to access it while adhering to the best practices set up by both the digital archiving community and the resources at my disposal. The disks with these issues amounted to nearly 1/5 of the imaged collection, and many hours of research and testing were put into how I could reprocess this information. Ultimately, I found myself faced with a choice – I could either preserve inaccurate representations of the disk by retaining the existing disk images or preserve inaccurate representations of the metadata by extracting extant files instead of preserving a disk image. The issue with preserving the metadata as it stood was that it was wrong to begin with, and the resources at hand didn’t provide a solution.
When thinking about how best to reprocess this information, I was drawn to this quote from a study undertaken by Julia Kim, the Digital Assets Manager at the Library of Congress:
“Most of the researchers emphasized that if it came to partially processed files or emulations and a significant time delay in processing, they would take unprocessed and relatively inauthentic files. Access by any means, and ease of access were stressed by the majority.”
“Researcher Interactions with Born-Digital: Out of the Frying Pan and into the Reading Room,” saaers.wordpress.com
While we certainly don’t want to prioritize patron opinion over archival standards, this quote made me question whether sacrificing access and preservation to retain imperfect metadata could truly be considered “best practice.”
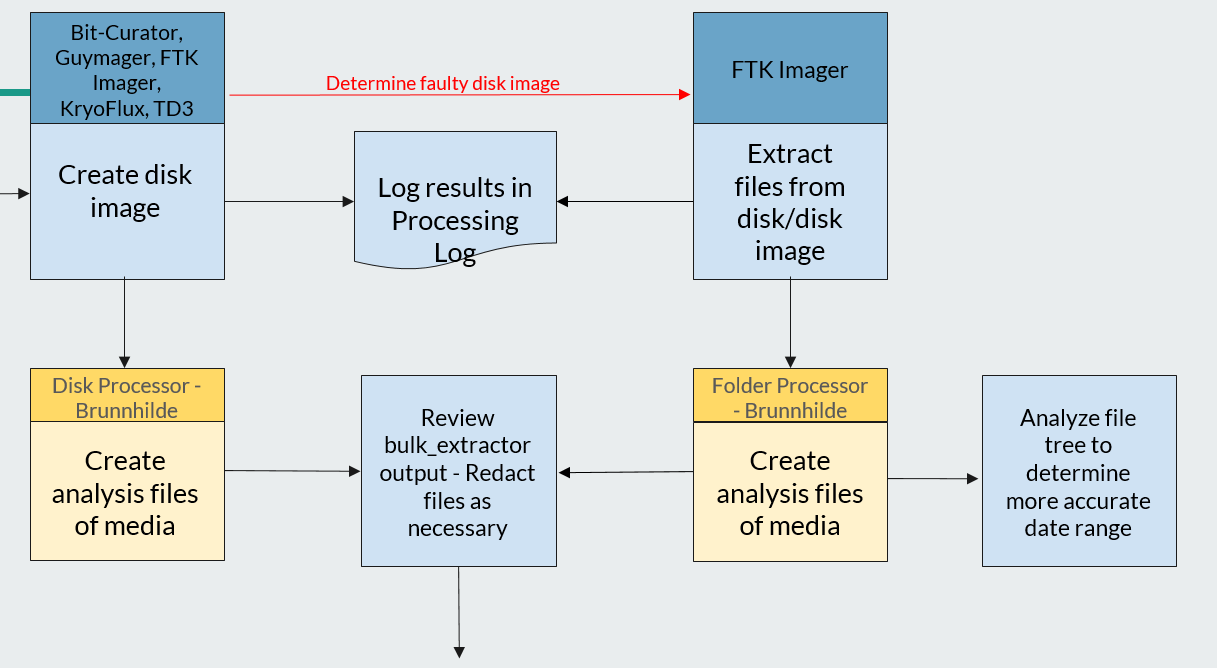
Working closely with the UT Libraries Digital Stewardship department, I created a workflow whereby I extracted files using FTK Imager and generated SIPS and a bulk_extractor report using the Canadian Center for Architecture’s Folder Processing Tool in the BitCurator environment. The only impact on the metadata was a change in the “Date Modified” field, which now showed the date the files were extracted and could be amended to reflect the most recent date in the file tree. While this is an unconventional approach to digital preservation, the resulting AIPs and DIPs are better representations of the original disks and will allow us to provide more comprehensive data for future researchers.
The amended workflow.
Our new results.
After my presentation, I had the opportunity to talk to a digital archivist about this workflow. We discussed how best practice is ultimately not about perfection, but about preserving and providing access to our materials and documenting the process. While somewhat contrasted from the theoretical approaches I’d both learned in class and adapted from online resources, this approach seemed more natural to me. It affirmed both my processing decisions and the opinions I’ve developed about what best practice in the archival community is and should be. This process has shown me how vital the user is to the archive, especially when developing workflows for digital materials.
As I mentioned in my previous post, I love having opportunities to exercise creativity and problem solving in this position. It’s even better when those opportunities lead to breakthroughs that help me grow professionally and enhance the data we provide patrons. I’m excited to see new developments in our born-digital workflow as we get closer to making this collection available to patrons. Check back soon for a (final?) update from me – I hope you’ve enjoyed learning more about the behind-the-scenes work of born-digital archiving.
A floppy disk from the Volz & Associates, Inc. collection.
Hello! This is Abbie Norris, back with an update on the born-digital Volz & Associates, Inc. collection. For those who haven’t read my previous blog post, I am the digital archives Graduate Research Assistant at the Alexander Architectural Archives. I’m currently working on the Volz & Associates, Inc. collection, which documents the work of a historic preservation firm based in Austin, Texas.
When I published my previous post, the collection was in the midst of being processed. I’m happy to report that processing for this collection is complete – all 813 floppy disks, CDs, zip disks, and flash drives of it. Processing is one of the first major stages of getting a collection from the donor to the public. It’s when the bulk of archival preservation happens. In this case, as in many born-digital collections, “processing” involved imaging (essentially, copying) the disks, capturing metadata like disk size and file types, and recording everything for documentation in the finding aid. We’re now able to determine the size of the collection, the types of files, and what we need to provide access to them.
One of the things I love about born-digital archiving is the problems that arise that require creative solutions. This is especially true for an archive’s pilot born-digital collection, as is the case for Volz. Items like CDs and floppy disks degrade at a faster rate than paper materials, meaning that sometimes you try to open a disk that physically appears fine, and it won’t show any of your files. One major question people have is, “If all of the information is stored on a CD, why do you have to copy the contents in a disk image? Why can’t you just continue opening the CD to access the contents?” Luckily, the answer is simple.
Imagine you have a 13th century codex and a 1990s floppy disk. Which one is easier for you to read? With the codex, all you have to do is open it. It will be fragile and you might not know the language in which it’s written, but much of the information held in the book will be visible to you. Now, consider the floppy disk. When was the last time you used one? Does your computer still have a floppy disk drive? More than likely, the answer is, “No.” Even if it does, think about the files on that disk. Can you still open a WordPerfect document from 1992?
Given that the Volz collection dates between 1980 and 2009, the types of files present on the disk vary widely. Some, like .txt and .tif files, are still widely accessible and are projected to remain active filetypes in the future. Others, like .jpeg, are still accessible but are not recommended for preservation because of their lower quality and the potential for their use to cease. Finally, there are the files that you try to open with modern software…and nothing works. These files can be either old versions of proprietary software and discontinued software.
This is where creative solutions come in. There are a variety of tools, many borrowed from the criminal forensics world, that allows us to look at files from twenty years ago. Because the digital archive field is still developing and many of the projects use open access tools, the software an archive uses to read and provide access to old files can resemble a patchwork quilt. Now that I know exactly what types of files are in the collection, I love exploring access solutions and finding answers to questions that have persisted since I began working here.
In many ways, finishing processing feels like finishing the first segment of a relay race. I feel accomplished for finishing a major task, but there is still a long way to go. Now that processing is complete, we have to finish writing the finding aid and establish methods for researchers to access the collection. It’s going to be an exciting few months, so check back here to learn about what providing access to a born-digital collection looks like at the Alexander Architectural Archives.
Blog from the University of Texas Architecture and Planning Library